Research
Recent research publications
2026

Fanar 2.0: Arabic Generative AI Stack
We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
@misc{fanar2026fanar20arabicgenerative,
title={Fanar 2.0: Arabic Generative AI Stack},
author={Fanar Team},
year={2026},
eprint={2603.16397},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2603.16397},
}
2025

Beyond the Leaderboard: Understanding Performance Disparities in Large Language Models via Model Diffing
As fine-tuning becomes the dominant paradigm for improving large language models (LLMs), understanding what changes during this process is increasingly important. Traditional benchmarking often fails to explain _why_ one model outperforms another. In this work, we use model diffing, a mechanistic interpretability approach, to analyze the specific capability differences between Gemma-2-9b-it and a SimPO-enhanced variant. Using crosscoders, we identify and categorize latent representations that differentiate the two models. We find that SimPO acquired latent concepts predominantly enhance safety mechanisms (+32.8%), multilingual capabilities (+43.8%), and instruction-following (+151.7%), while its additional training also reduces emphasis on model self-reference (-44.1%) and hallucination management (-68.5%). Our analysis shows that model diffing can yield fine-grained insights beyond leaderboard metrics, attributing performance gaps to concrete mechanistic capabilities. This approach offers a transparent and targeted framework for comparing LLMs.
@inproceedings{boughorbel-etal-2025-beyond,
title = "Beyond the Leaderboard: Understanding Performance Disparities in Large Language Models via Model Diffing",
author = "Boughorbel, Sabri and
Dalvi, Fahim and
Durrani, Nadir and
Hawasly, Majd",
booktitle = "Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2025",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.emnlp-main.1598/",
doi = "10.18653/v1/2025.emnlp-main.1598",
pages = "31360--31371",
ISBN = "979-8-89176-332-6"
}

Editing Across Languages: A Survey of Multilingual Knowledge Editing
While Knowledge Editing has been extensively studied in monolingual settings, it remains underexplored in multilingual contexts. This survey systematizes recent research on Multilingual Knowledge Editing (MKE), a growing subdomain of model editing focused on ensuring factual edits generalize reliably across languages. We present a comprehensive taxonomy of MKE methods, covering parameter-based, memory-based, fine-tuning, and hypernetwork approaches. We survey available benchmarks, summarize key findings on method effectiveness and transfer patterns, and identify persistent challenges such as cross-lingual propagation, language anisotropy, and limited evaluation for low-resource and culturally specific languages. We also discuss broader concerns such as stability and scalability of multilingual edits. Our analysis consolidates a rapidly evolving area and lays the groundwork for future progress in editable language-aware LLMs.
@inproceedings{durrani-etal-2025-editing,
title = "Editing Across Languages: A Survey of Multilingual Knowledge Editing",
author = "Durrani, Nadir and
Mousi, Basel and
Dalvi, Fahim",
booktitle = "Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2025",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.emnlp-main.803/",
doi = "10.18653/v1/2025.emnlp-main.803",
pages = "15906--15918",
ISBN = "979-8-89176-332-6"
}
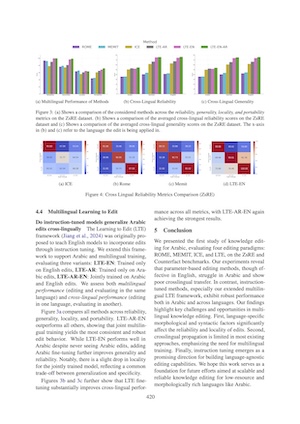
An Exploration of Knowledge Editing for Arabic
While Knowledge Editing (KE) has been widely explored in English, its behavior in morphologically rich languages like Arabic remains underexamined. In this work, we present the first study of Arabic KE. We evaluate four methods (ROME, MEMIT, ICE, and LTE) on Arabic translations of the ZsRE and Counterfact benchmarks, analyzing both multilingual and cross-lingual settings. Our experiments on Llama-2-7B-chat show show that parameter-based methods struggle with cross-lingual generalization, while instruction-tuned methods perform more robustly. We extend Learning-To-Edit (LTE) to a multilingual setting and show that joint Arabic-English training improves both editability and transfer. We release Arabic KE benchmarks and multilingual training for LTE data to support future research.
@inproceedings{mousi-etal-2025-exploration,
title = "An Exploration of Knowledge Editing for {A}rabic",
author = "Mousi, Basel and
Durrani, Nadir and
Dalvi, Fahim",
booktitle = "Proceedings of The Third Arabic Natural Language Processing Conference",
month = nov,
year = "2025",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.arabicnlp-main.34/",
doi = "10.18653/v1/2025.arabicnlp-main.34",
pages = "417--424",
ISBN = "979-8-89176-352-4"
}

From Words to Waves: Analyzing Concept Formation in Speech and Text-Based Foundation Models
The emergence of large language models has demonstrated that systems trained solely on text can acquire extensive world knowledge, develop reasoning capabilities, and internalize abstract semantic concepts - showcasing properties that can be associated with general intelligence. This raises an intriguing question: Do such concepts emerge in models trained on other modalities, such as speech? Furthermore, when models are trained jointly on multiple modalities: Do they develop a richer, more structured semantic understanding? To explore this, we analyze the conceptual structures learned by speech and textual models both individually and jointly. We employ Latent Concept Analysis, an unsupervised method for uncovering and interpreting latent representations in neural networks, to examine how semantic abstractions form across modalities. To support reproducibility, we have released our code along with a curated audio version of the SST-2 dataset for public access.
@inproceedings{ersoy25_interspeech,
title = {{From Words to Waves: Analyzing Concept Formation in Speech and Text-Based Foundation Models}},
author = {Asim Ersoy and Basel Ahmad Mousi and Shammur Absar Chowdhury and Firoj Alam and Fahim I Dalvi and Nadir Durrani},
year = {2025},
booktitle = {{Interspeech 2025}},
pages = {241--245},
doi = {10.21437/Interspeech.2025-2180},
issn = {2958-1796},
}

AraDiCE: Benchmarks for Dialectal and Cultural Capabilities in LLMs
Arabic, with its rich diversity of dialects, remains significantly underrepresented in Large Language Models, particularly in dialectal variations. We address this gap by introducing seven synthetic datasets in dialects alongside Modern Standard Arabic (MSA), created using Machine Translation (MT) combined with human post-editing. We present AraDiCE, a benchmark for Arabic Dialect and Cultural Evaluation. We evaluate LLMs on dialect comprehension and generation, focusing specifically on low-resource Arabic dialects. Additionally, we introduce the first-ever fine-grained benchmark designed to evaluate cultural awareness across the Gulf, Egypt, and Levant regions, providing a novel dimension to LLM evaluation. Our findings demonstrate that while Arabic-specific models like Jais and AceGPT outperform multilingual models on dialectal tasks, significant challenges persist in dialect identification, generation, and translation.
@inproceedings{mousi-etal-2025-aradice,
title = "{A}ra{D}i{CE}: Benchmarks for Dialectal and Cultural Capabilities in {LLM}s",
author = "Mousi, Basel and
Durrani, Nadir and
Ahmad, Fatema and
Hasan, Md. Arid and
Hasanain, Maram and
Kabbani, Tameem and
Dalvi, Fahim and
Chowdhury, Shammur Absar and
Alam, Firoj",
booktitle = "Proceedings of the 31st International Conference on Computational Linguistics",
month = jan,
year = "2025",
address = "Abu Dhabi, UAE",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.coling-main.283/",
pages = "4186--4218",
abstract = "Arabic, with its rich diversity of dialects, remains significantly underrepresented in Large Language Models, particularly in dialectal variations. We address this gap by introducing seven synthetic datasets in dialects alongside Modern Standard Arabic (MSA), created using Machine Translation (MT) combined with human post-editing. We present AraDiCE, a benchmark for Arabic Dialect and Cultural Evaluation. We evaluate LLMs on dialect comprehension and generation, focusing specifically on low-resource Arabic dialects. Additionally, we introduce the first-ever fine-grained benchmark designed to evaluate cultural awareness across the Gulf, Egypt, and Levant regions, providing a novel dimension to LLM evaluation. Our findings demonstrate that while Arabic-specific models like Jais and AceGPT outperform multilingual models on dialectal tasks, significant challenges persist in dialect identification, generation, and translation. This work contributes {\ensuremath{\approx}}45K post-edited samples, a cultural benchmark, and highlights the importance of tailored training to improve LLM performance in capturing the nuances of diverse Arabic dialects and cultural contexts. We have released the dialectal translation models and benchmarks developed in this study (https://huggingface.co/datasets/QCRI/AraDiCE)",
}

Fanar: An Arabic-Centric Multimodal Generative AI Platform
We present Fanar, a platform for Arabic-centric multimodal generative AI systems, that supports language, speech and image generation tasks. At the heart of Fanar are Fanar Star and Fanar Prime, two highly capable Arabic Large Language Models (LLMs) that are best in the class on well established benchmarks for similar sized models. Fanar Star is a 7B (billion) parameter model that was trained from scratch on nearly 1 trillion clean and deduplicated Arabic, English and Code tokens. Fanar Prime is a 9B parameter model continually trained on the Gemma-2 9B base model on the same 1 trillion token set. Both models are concurrently deployed and designed to address different types of prompts transparently routed through a custom-built orchestrator. The Fanar platform provides many other capabilities including a customized Islamic Retrieval Augmented Generation (RAG) system for handling religious prompts, a Recency RAG for summarizing information about current or recent events that have occurred after the pre-training data cut-off date. The platform provides additional cognitive capabilities including in-house bilingual speech recognition that supports multiple Arabic dialects, voice and image generation that is fine-tuned to better reflect regional characteristics. Finally, Fanar provides an attribution service that can be used to verify the authenticity of fact based generated content.
@misc{fanar,
title={Fanar: An Arabic-Centric Multimodal Generative AI Platform},
author={Fanar Team},
year={2025},
eprint={2501.13944},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.13944},
}
2024

Latent Concept-based Explanation of NLP Models
Interpreting and understanding the predictions made by deep learning models poses a formidable challenge due to their inherently opaque nature. Many previous efforts aimed at explaining these predictions rely on input features, specifically, the words within NLP models. However, such explanations are often less informative due to the discrete nature of these words and their lack of contextual verbosity. To address this limitation, we introduce the Latent Concept Attribution method (LACOAT), which generates explanations for predictions based on latent concepts. Our foundational intuition is that a word can exhibit multiple facets, contingent upon the context in which it is used. Therefore, given a word in context, the latent space derived from our training process reflects a specific facet of that word. LACOAT functions by mapping the representations of salient input words into the training latent space, allowing it to provide latent context-based explanations of the prediction.
@inproceedings{yu-etal-2024-latent,
title = "Latent Concept-based Explanation of {NLP} Models",
author = "Yu, Xuemin and
Dalvi, Fahim and
Durrani, Nadir and
Nouri, Marzia and
Sajjad, Hassan",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.emnlp-main.692",
doi = "10.18653/v1/2024.emnlp-main.692",
pages = "12435--12459",
abstract = "Interpreting and understanding the predictions made by deep learning models poses a formidable challenge due to their inherently opaque nature. Many previous efforts aimed at explaining these predictions rely on input features, specifically, the words within NLP models. However, such explanations are often less informative due to the discrete nature of these words and their lack of contextual verbosity. To address this limitation, we introduce the Latent Concept Attribution method (LACOAT), which generates explanations for predictions based on latent concepts. Our foundational intuition is that a word can exhibit multiple facets, contingent upon the context in which it is used. Therefore, given a word in context, the latent space derived from our training process reflects a specific facet of that word. LACOAT functions by mapping the representations of salient input words into the training latent space, allowing it to provide latent context-based explanations of the prediction.",
}

Exploring Alignment in Shared Cross-lingual Spaces
Despite their remarkable ability to capture linguistic nuances across diverse languages, questions persist regarding the degree of alignment between languages in multilingual embeddings. Drawing inspiration from research on high-dimensional representations in neural language models, we employ clustering to uncover latent concepts within multilingual models. Our analysis focuses on quantifying the alignment and overlap of these concepts across various languages within the latent space. To this end, we introduce two metrics CALIGN and COLAP aimed at quantifying these aspects, enabling a deeper exploration of multilingual embeddings. Our study encompasses three multilingual models (mT5, mBERT, and XLM-R) and three downstream tasks (Machine Translation, Named Entity Recognition, and Sentiment Analysis). Key findings from our analysis include: i) deeper layers in the network demonstrate increased cross-lingual alignment due to the presence of language-agnostic concepts, ii) fine-tuning of the models enhances alignment within the latent space, and iii) such task-specific calibration helps in explaining the emergence of zero-shot capabilities in the models.
@inproceedings{mousi2024exploring,
title = "Exploring Alignment in Shared Cross-lingual Spaces",
author = "Mousi, Basel and
Durrani, Nadir and
Dalvi, Fahim and
Hawasly, Majd and
Abdelali, Ahmed",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.acl-long.344",
pages = "6326--6348",
abstract = "Despite their remarkable ability to capture linguistic nuances across diverse languages, questions persist regarding the degree of alignment between languages in multilingual embeddings. Drawing inspiration from research on high-dimensional representations in neural language models, we employ clustering to uncover latent concepts within multilingual models. Our analysis focuses on quantifying the alignment and overlap of these concepts across various languages within the latent space. To this end, we introduce two metrics CALIGN and COLAP aimed at quantifying these aspects, enabling a deeper exploration of multilingual embeddings. Our study encompasses three multilingual models (mT5, mBERT, and XLM-R) and three downstream tasks (Machine Translation, Named Entity Recognition, and Sentiment Analysis). Key findings from our analysis include: i) deeper layers in the network demonstrate increased cross-lingual alignment due to the presence of language-agnostic concepts, ii) fine-tuning of the models enhances alignment within the latent space, and iii) such task-specific calibration helps in explaining the emergence of zero-shot capabilities in the models.",
}

LLMeBench: A Flexible Framework for Accelerating LLMs Benchmarking
The recent development and success of Large Language Models (LLMs) necessitate an evaluation of their performance across diverse NLP tasks in different languages. Although several frameworks have been developed and made publicly available, their customization capabilities for specific tasks and datasets are often complex for different users. In this study, we introduce the LLMeBench framework, which can be seamlessly customized to evaluate LLMs for any NLP task, regardless of language. The framework features generic dataset loaders, several model providers, and pre-implements most standard evaluation metrics. It supports in-context learning with zero- and few-shot settings. A specific dataset and task can be evaluated for a given LLM in less than 20 lines of code while allowing full flexibility to extend the framework for custom datasets, models, or tasks. The framework has been tested on 31 unique NLP tasks using 53 publicly available datasets within 90 experimental setups, involving approximately 296K data points. We open-sourced LLMeBench for the community (https://github.com/qcri/LLMeBench/) and a video demonstrating the framework is available online (https://youtu.be/9cC2m_abk3A).
@inproceedings{dalvi-etal-2024-llmebench,
title = "{LLM}e{B}ench: A Flexible Framework for Accelerating {LLM}s Benchmarking",
author = "Dalvi, Fahim and
Hasanain, Maram and
Boughorbel, Sabri and
Mousi, Basel and
Abdaljalil, Samir and
Nazar, Nizi and
Abdelali, Ahmed and
Chowdhury, Shammur Absar and
Mubarak, Hamdy and
Ali, Ahmed and
Hawasly, Majd and
Durrani, Nadir and
Alam, Firoj",
editor = "Aletras, Nikolaos and
De Clercq, Orphee",
booktitle = "Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = mar,
year = "2024",
address = "St. Julians, Malta",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.eacl-demo.23",
pages = "214--222",
abstract = "The recent development and success of Large Language Models (LLMs) necessitate an evaluation of their performance across diverse NLP tasks in different languages. Although several frameworks have been developed and made publicly available, their customization capabilities for specific tasks and datasets are often complex for different users. In this study, we introduce the LLMeBench framework, which can be seamlessly customized to evaluate LLMs for any NLP task, regardless of language. The framework features generic dataset loaders, several model providers, and pre-implements most standard evaluation metrics. It supports in-context learning with zero- and few-shot settings. A specific dataset and task can be evaluated for a given LLM in less than 20 lines of code while allowing full flexibility to extend the framework for custom datasets, models, or tasks. The framework has been tested on 31 unique NLP tasks using 53 publicly available datasets within 90 experimental setups, involving approximately 296K data points. We open-sourced LLMeBench for the community (https://github.com/qcri/LLMeBench/) and a video demonstrating the framework is available online (https://youtu.be/9cC2m{\_}abk3A).",
}

Scaling up Discovery of Latent Concepts in Deep NLP Models
Despite the revolution caused by deep NLP models, they remain black boxes, necessitating research to understand their decision-making processes. A recent work by Dalvi et al. (2022) carried out representation analysis through the lens of clustering latent spaces within pre-trained models (PLMs), but that approach is limited to small scale due to the high cost of running Agglomerative hierarchical clustering. This paper studies clustering algorithms in order to scale the discovery of encoded concepts in PLM representations to larger datasets and models. We propose metrics for assessing the quality of discovered latent concepts and use them to compare the studied clustering algorithms. We found that K-Means-based concept discovery significantly enhances efficiency while maintaining the quality of the obtained concepts. Furthermore, we demonstrate the practicality of this newfound efficiency by scaling latent concept discovery to LLMs and phrasal concepts.
@inproceedings{hawasly-etal-2024-scaling,
title = "Scaling up Discovery of Latent Concepts in Deep {NLP} Models",
author = "Hawasly, Majd and
Dalvi, Fahim and
Durrani, Nadir",
editor = "Graham, Yvette and
Purver, Matthew",
booktitle = "Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = mar,
year = "2024",
address = "St. Julian{'}s, Malta",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.eacl-long.48",
pages = "793--806",
abstract = "Despite the revolution caused by deep NLP models, they remain black boxes, necessitating research to understand their decision-making processes. A recent work by Dalvi et al. (2022) carried out representation analysis through the lens of clustering latent spaces within pre-trained models (PLMs), but that approach is limited to small scale due to the high cost of running Agglomerative hierarchical clustering. This paper studies clustering algorithms in order to scale the discovery of encoded concepts in PLM representations to larger datasets and models. We propose metrics for assessing the quality of discovered latent concepts and use them to compare the studied clustering algorithms. We found that K-Means-based concept discovery significantly enhances efficiency while maintaining the quality of the obtained concepts. Furthermore, we demonstrate the practicality of this newfound efficiency by scaling latent concept discovery to LLMs and phrasal concepts.",
}
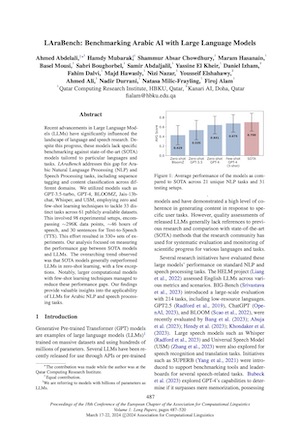
LAraBench: Benchmarking Arabic AI with Large Language Models
Recent advancements in Large Language Models (LLMs) have significantly influenced the landscape of language and speech research. Despite this progress, these models lack specific benchmarking against state-of-the-art (SOTA) models tailored to particular languages and tasks. LAraBench addresses this gap for Arabic Natural Language Processing (NLP) and Speech Processing tasks, including sequence tagging and content classification across different domains. We utilized models such as GPT-3.5-turbo, GPT-4, BLOOMZ, Jais-13b-chat, Whisper, and USM, employing zero and few-shot learning techniques to tackle 33 distinct tasks across 61 publicly available datasets. This involved 98 experimental setups, encompassing ~296K data points, ~46 hours of speech, and 30 sentences for Text-to-Speech (TTS). This effort resulted in 330+ sets of experiments. Our analysis focused on measuring the performance gap between SOTA models and LLMs. The overarching trend observed was that SOTA models generally outperformed LLMs in zero-shot learning, with a few exceptions. Notably, larger computational models with few-shot learning techniques managed to reduce these performance gaps. Our findings provide valuable insights into the applicability of LLMs for Arabic NLP and speech processing tasks.
@inproceedings{abdelali-etal-2024-larabench,
title = "{LA}ra{B}ench: Benchmarking {A}rabic {AI} with Large Language Models",
author = "Abdelali, Ahmed and
Mubarak, Hamdy and
Chowdhury, Shammur and
Hasanain, Maram and
Mousi, Basel and
Boughorbel, Sabri and
Abdaljalil, Samir and
El Kheir, Yassine and
Izham, Daniel and
Dalvi, Fahim and
Hawasly, Majd and
Nazar, Nizi and
Elshahawy, Youssef and
Ali, Ahmed and
Durrani, Nadir and
Milic-Frayling, Natasa and
Alam, Firoj",
editor = "Graham, Yvette and
Purver, Matthew",
booktitle = "Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = mar,
year = "2024",
address = "St. Julian{'}s, Malta",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.eacl-long.30",
pages = "487--520",
abstract = "Recent advancements in Large Language Models (LLMs) have significantly influenced the landscape of language and speech research. Despite this progress, these models lack specific benchmarking against state-of-the-art (SOTA) models tailored to particular languages and tasks. LAraBench addresses this gap for Arabic Natural Language Processing (NLP) and Speech Processing tasks, including sequence tagging and content classification across different domains. We utilized models such as GPT-3.5-turbo, GPT-4, BLOOMZ, Jais-13b-chat, Whisper, and USM, employing zero and few-shot learning techniques to tackle 33 distinct tasks across 61 publicly available datasets. This involved 98 experimental setups, encompassing {\textasciitilde}296K data points, {\textasciitilde}46 hours of speech, and 30 sentences for Text-to-Speech (TTS). This effort resulted in 330+ sets of experiments. Our analysis focused on measuring the performance gap between SOTA models and LLMs. The overarching trend observed was that SOTA models generally outperformed LLMs in zero-shot learning, with a few exceptions. Notably, larger computational models with few-shot learning techniques managed to reduce these performance gaps. Our findings provide valuable insights into the applicability of LLMs for Arabic NLP and speech processing tasks.",
}
2023

Evaluating Neuron Interpretation Methods of NLP Models
Neuron interpretation offers valuable insights into how knowledge is structured within a deep neural network model. While a number of neuron interpretation methods have been proposed in the literature, the field lacks a comprehensive comparison among these methods. This gap hampers progress due to the absence of standardized metrics and benchmarks. The commonly used evaluation metric has limitations, and creating ground truth annotations for neurons is impractical. Addressing these challenges, we propose an evaluation framework based on voting theory. Our hypothesis posits that neurons consistently identified by different methods carry more significant information. We rigorously assess our framework across a diverse array of neuron interpretation methods. Notable findings include: i) despite the theoretical differences among the methods, neuron ranking methods share over 60% of their rankings when identifying salient neurons, ii) the neuron interpretation methods are most sensitive to the last layer representations, iii) Probeless neuron ranking emerges as the most consistent method.
@inproceedings{NEURIPS2023_eef6cb60,
author = {Fan, Yimin and Dalvi, Fahim and Durrani, Nadir and Sajjad, Hassan},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Oh and T. Naumann and A. Globerson and K. Saenko and M. Hardt and S. Levine},
pages = {75644--75668},
publisher = {Curran Associates, Inc.},
title = {Evaluating Neuron Interpretation Methods of NLP Models},
url = {https://proceedings.neurips.cc/paper_files/paper/2023/file/eef6cb60fd59b32d35718e176b4b08d6-Paper-Conference.pdf},
volume = {36},
year = {2023}
}

Discovering Salient Neurons in Deep NLP models
While a lot of work has been done in understanding representations learned within deep NLP models and what knowledge they capture, work done towards analyzing individual neurons is relatively sparse. We present a technique called Linguistic Correlation Analysis to extract salient neurons in the model, with respect to any extrinsic property, with the goal of understanding how such knowledge is preserved within neurons. We carry out a fine-grained analysis to answer the following questions: (i) can we identify subsets of neurons in the network that learn a specific linguistic property? (ii) is a certain linguistic phenomenon in a given model localized (encoded in few individual neurons) or distributed across many neurons? (iii) how redundantly is the information preserved? (iv) how does fine-tuning pre-trained models towards downstream NLP tasks impact the learned linguistic knowledge? (v) how do models vary in learning different linguistic properties? Our data-driven, quantitative analysis illuminates interesting findings: (i) we found small subsets of neurons that can predict different linguistic tasks; (ii) neurons capturing basic lexical information, such as suffixation, are localized in the lowermost layers; (iii) neurons learning complex concepts, such as syntactic role, are predominantly found in middle and higher layers; (iv) salient linguistic neurons are relocated from higher to lower layers during transfer learning, as the network preserves the higher layers for task-specific information; (v) we found interesting differences across pre-trained models regarding how linguistic information is preserved within them; and (vi) we found that concepts exhibit similar neuron distribution across different languages in the multilingual transformer models. Our code is publicly available as part of the NeuroX toolkit (Dalvi et al., 2023).
@article{JMLR:v24:23-0074,
author = {Nadir Durrani and Fahim Dalvi and Hassan Sajjad},
title = {Discovering Salient Neurons in deep NLP models},
journal = {Journal of Machine Learning Research},
year = {2023},
volume = {24},
number = {362},
pages = {1--40},
url = {http://jmlr.org/papers/v24/23-0074.html}
}

Can LLMs Facilitate Interpretation of Pre-trained Language Models?
Work done to uncover the knowledge encoded within pre-trained language models rely on annotated corpora or human-in-the-loop methods. However, these approaches are limited in terms of scalability and the scope of interpretation. We propose using a large language model, ChatGPT, as an annotator to enable fine-grained interpretation analysis of pre-trained language models. We discover latent concepts within pre-trained language models by applying agglomerative hierarchical clustering over contextualized representations and then annotate these concepts using ChatGPT. Our findings demonstrate that ChatGPT produces accurate and semantically richer annotations compared to human-annotated concepts. Additionally, we showcase how GPT-based annotations empower interpretation analysis methodologies of which we demonstrate two: probing frameworks and neuron interpretation. To facilitate further exploration and experimentation in the field, we make available a substantial ConceptNet dataset (TCN) comprising 39,000 annotated concepts.
@inproceedings{mousi-etal-2023-llms,
title = "Can {LLM}s Facilitate Interpretation of Pre-trained Language Models?",
author = "Mousi, Basel and
Durrani, Nadir and
Dalvi, Fahim",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.emnlp-main.196",
doi = "10.18653/v1/2023.emnlp-main.196",
pages = "3248--3268",
abstract = "Work done to uncover the knowledge encoded within pre-trained language models rely on annotated corpora or human-in-the-loop methods. However, these approaches are limited in terms of scalability and the scope of interpretation. We propose using a large language model, ChatGPT, as an annotator to enable fine-grained interpretation analysis of pre-trained language models. We discover latent concepts within pre-trained language models by applying agglomerative hierarchical clustering over contextualized representations and then annotate these concepts using ChatGPT. Our findings demonstrate that ChatGPT produces accurate and semantically richer annotations compared to human-annotated concepts. Additionally, we showcase how GPT-based annotations empower interpretation analysis methodologies of which we demonstrate two: probing frameworks and neuron interpretation. To facilitate further exploration and experimentation in the field, we make available a substantial ConceptNet dataset (TCN) comprising 39,000 annotated concepts.",
}

NeuroX Library for Neuron Analysis of Deep NLP Models
Neuron analysis provides insights into how knowledge is structured in representations and discovers the role of neurons in the network. In addition to developing an understanding of our models, neuron analysis enables various applications such as debiasing, domain adaptation and architectural search. We present NeuroX, a comprehensive open-source toolkit to conduct neuron analysis of natural language processing models. It implements various interpretation methods under a unified API, and provides a framework for data processing and evaluation, thus making it easier for researchers and practitioners to perform neuron analysis. The Python toolkit is available at https://www.github.com/fdalvi/NeuroX.
@inproceedings{dalvi-etal-2023-neurox,
title = "{N}euro{X} Library for Neuron Analysis of Deep {NLP} Models",
author = "Dalvi, Fahim and
Sajjad, Hassan and
Durrani, Nadir",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-demo.21",
doi = "10.18653/v1/2023.acl-demo.21",
pages = "226--234",
abstract = "Neuron analysis provides insights into how knowledge is structured in representations and discovers the role of neurons in the network. In addition to developing an understanding of our models, neuron analysis enables various applications such as debiasing, domain adaptation and architectural search. We present NeuroX, a comprehensive open-source toolkit to conduct neuron analysis of natural language processing models. It implements various interpretation methods under a unified API, and provides a framework for data processing and evaluation, thus making it easier for researchers and practitioners to perform neuron analysis. The Python toolkit is available at https://www.github.com/fdalvi/NeuroX.Demo Video available at: https://youtu.be/mLhs2YMx4u8",
}

NxPlain: A Web-based Tool for Discovery of Latent Concepts
The proliferation of deep neural networks in various domains has seen an increased need for the interpretability of these models, especially in scenarios where fairness and trust are as important as model performance. A lot of independent work is being carried out to: i) analyze what linguistic and non-linguistic knowledge is learned within these models, and ii) highlight the salient parts of the input. We present NxPlain, a web-app that provides an explanation of a model{'}s prediction using latent concepts. NxPlain discovers latent concepts learned in a deep NLP model, provides an interpretation of the knowledge learned in the model, and explains its predictions based on the used concepts. The application allows users to browse through the latent concepts in an intuitive order, letting them efficiently scan through the most salient concepts with a global corpus-level view and a local sentence-level view. Our tool is useful for debugging, unraveling model bias, and for highlighting spurious correlations in a model. A hosted demo is available here: https://nxplain.qcri.org
@inproceedings{dalvi-etal-2023-nxplain,
title = "{N}x{P}lain: A Web-based Tool for Discovery of Latent Concepts",
author = "Dalvi, Fahim and
Durrani, Nadir and
Sajjad, Hassan and
Jaban, Tamim and
Husaini, Mus{'}ab and
Abbas, Ummar",
booktitle = "Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations",
month = may,
year = "2023",
address = "Dubrovnik, Croatia",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.eacl-demo.10",
doi = "10.18653/v1/2023.eacl-demo.10",
pages = "75--83",
abstract = "The proliferation of deep neural networks in various domains has seen an increased need for the interpretability of these models, especially in scenarios where fairness and trust are as important as model performance. A lot of independent work is being carried out to: i) analyze what linguistic and non-linguistic knowledge is learned within these models, and ii) highlight the salient parts of the input. We present NxPlain, a web-app that provides an explanation of a model{'}s prediction using latent concepts. NxPlain discovers latent concepts learned in a deep NLP model, provides an interpretation of the knowledge learned in the model, and explains its predictions based on the used concepts. The application allows users to browse through the latent concepts in an intuitive order, letting them efficiently scan through the most salient concepts with a global corpus-level view and a local sentence-level view. Our tool is useful for debugging, unraveling model bias, and for highlighting spurious correlations in a model. A hosted demo is available here: https://nxplain.qcri.org",
}
ConceptX: A Framework for Latent Concept Analysis
The opacity of deep neural networks remains a challenge in deploying solutions where explanation is as important as precision. We present ConceptX, a human-in-the-loop framework for interpreting and annotating latent representational space in pre-trained Language Models (pLMs). We use an unsupervised method to discover concepts learned in these models and enable a graphical interface for humans to generate explanations for the concepts. To facilitate the process, we provide auto-annotations of the concepts (based on traditional linguistic ontologies). Such annotations enable development of a linguistic resource that directly represents latent concepts learned within deep NLP models. These include not just traditional linguistic concepts, but also task-specific or sensitive concepts (words grouped based on gender or religious connotation) that helps the annotators to mark bias in the model. The framework consists of two parts (i) concept discovery and (ii) annotation platform.
@article{Alam_Dalvi_Durrani_Sajjad_Khan_Xu_2023,
title={ConceptX: A Framework for Latent Concept Analysis},
volume={37},
url={https://ojs.aaai.org/index.php/AAAI/article/view/27057},
DOI={10.1609/aaai.v37i13.27057},
abstractNote={The opacity of deep neural networks remains a challenge in deploying solutions where explanation is as important as precision. We present ConceptX, a human-in-the-loop framework for interpreting and annotating latent representational space in pre-trained Language Models (pLMs). We use an unsupervised method to discover concepts learned in these models and enable a graphical interface for humans to generate explanations for the concepts. To facilitate the process, we provide auto-annotations of the concepts (based on traditional linguistic ontologies). Such annotations enable development of a linguistic resource that directly represents latent concepts learned within deep NLP models. These include not just traditional linguistic concepts, but also task-specific or sensitive concepts (words grouped based on gender or religious connotation) that helps the annotators to mark bias in the model. The framework consists of two parts (i) concept discovery and (ii) annotation platform.},
number={13},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Alam, Firoj and Dalvi, Fahim and Durrani, Nadir and Sajjad, Hassan and Khan, Abdul Rafae and Xu, Jia},
year={2023},
month={Sep.},
pages={16395-16397}
}

On the effect of dropping layers of pre-trained transformer models
Transformer-based NLP models are trained using hundreds of millions or even billions of parameters, limiting their applicability in computationally constrained environments. While the number of parameters generally correlates with performance, it is not clear whether the entire network is required for a downstream task. Motivated by the recent work on pruning and distilling pre-trained models, we explore strategies to drop layers in pre-trained models, and observe the effect of pruning on downstream GLUE tasks. We were able to prune BERT, RoBERTa and XLNet models up to 40%, while maintaining up to 98% of their original performance. Additionally we show that our pruned models are on par with those built using knowledge distillation, both in terms of size and performance. Our experiments yield interesting observations such as: (i) the lower layers are most critical to maintain downstream task performance, (ii) some tasks such as paraphrase detection and sentence similarity are more robust to the dropping of layers, and (iii) models trained using different objective function exhibit different learning patterns and w.r.t the layer dropping.
@article{SAJJAD2023101429,
title = {On the effect of dropping layers of pre-trained transformer models},
journal = {Computer Speech & Language},
volume = {77},
pages = {101429},
year = {2023},
issn = {0885-2308},
doi = {https://doi.org/10.1016/j.csl.2022.101429},
url = {https://www.sciencedirect.com/science/article/pii/S0885230822000596},
author = {Hassan Sajjad and Fahim Dalvi and Nadir Durrani and Preslav Nakov},
keywords = {Pre-trained transformer models, Efficient transfer learning, Interpretation and analysis},
abstract = {Transformer-based NLP models are trained using hundreds of millions or even billions of parameters, limiting their applicability in computationally constrained environments. While the number of parameters generally correlates with performance, it is not clear whether the entire network is required for a downstream task. Motivated by the recent work on pruning and distilling pre-trained models, we explore strategies to drop layers in pre-trained models, and observe the effect of pruning on downstream GLUE tasks. We were able to prune BERT, RoBERTa and XLNet models up to 40%, while maintaining up to 98% of their original performance. Additionally we show that our pruned models are on par with those built using knowledge distillation, both in terms of size and performance. Our experiments yield interesting observations such as: (i) the lower layers are most critical to maintain downstream task performance, (ii) some tasks such as paraphrase detection and sentence similarity are more robust to the dropping of layers, and (iii) models trained using different objective function exhibit different learning patterns and w.r.t the layer dropping.}
}
2022

On the Transformation of Latent Space in Fine-Tuned NLP Models
We study the evolution of latent space in fine-tuned NLP models. Different from the commonly used probing-framework, we opt for an unsupervised method to analyze representations. More specifically, we discover latent concepts in the representational space using hierarchical clustering. We then use an alignment function to gauge the similarity between the latent space of a pre-trained model and its fine-tuned version. We use traditional linguistic concepts to facilitate our understanding and also study how the model space transforms towards task-specific information. We perform a thorough analysis, comparing pre-trained and fine-tuned models across three models and three downstream tasks. The notable findings of our work are: i) the latent space of the higher layers evolve towards task-specific concepts, ii) whereas the lower layers retain generic concepts acquired in the pre-trained model, iii) we discovered that some concepts in the higher layers acquire polarity towards the output class, and iv) that these concepts can be used for generating adversarial triggers.
@inproceedings{durrani-etal-2022-transformation,
title = "On the Transformation of Latent Space in Fine-Tuned {NLP} Models",
author = "Durrani, Nadir and
Sajjad, Hassan and
Dalvi, Fahim and
Alam, Firoj",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.emnlp-main.97",
doi = "10.18653/v1/2022.emnlp-main.97",
pages = "1495--1516",
abstract = "We study the evolution of latent space in fine-tuned NLP models. Different from the commonly used probing-framework, we opt for an unsupervised method to analyze representations. More specifically, we discover latent concepts in the representational space using hierarchical clustering. We then use an alignment function to gauge the similarity between the latent space of a pre-trained model and its fine-tuned version. We use traditional linguistic concepts to facilitate our understanding and also study how the model space transforms towards task-specific information. We perform a thorough analysis, comparing pre-trained and fine-tuned models across three models and three downstream tasks. The notable findings of our work are: i) the latent space of the higher layers evolve towards task-specific concepts, ii) whereas the lower layers retain generic concepts acquired in the pre-trained model, iii) we discovered that some concepts in the higher layers acquire polarity towards the output class, and iv) that these concepts can be used for generating adversarial triggers.",
}
Post-hoc analysis of Arabic transformer models
Arabic is a Semitic language which is widely spoken with many dialects. Given the success of pre-trained language models, many transformer models trained on Arabic and its dialects have surfaced. While there have been an extrinsic evaluation of these models with respect to downstream NLP tasks, no work has been carried out to analyze and compare their internal representations. We probe how linguistic information is encoded in the transformer models, trained on different Arabic dialects. We perform a layer and neuron analysis on the models using morphological tagging tasks for different dialects of Arabic and a dialectal identification task. Our analysis enlightens interesting findings such as: i) word morphology is learned at the lower and middle layers, ii) while syntactic dependencies are predominantly captured at the higher layers, iii) despite a large overlap in their vocabulary, the MSA-based models fail to capture the nuances of Arabic dialects, iv) we found that neurons in embedding layers are polysemous in nature, while the neurons in middle layers are exclusive to specific properties.
@inproceedings{abdelali-etal-2022-post,
title = "Post-hoc analysis of {A}rabic transformer models",
author = "Abdelali, Ahmed and
Durrani, Nadir and
Dalvi, Fahim and
Sajjad, Hassan",
booktitle = "Proceedings of the Fifth BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates (Hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.blackboxnlp-1.8",
doi = "10.18653/v1/2022.blackboxnlp-1.8",
pages = "91--103",
abstract = "Arabic is a Semitic language which is widely spoken with many dialects. Given the success of pre-trained language models, many transformer models trained on Arabic and its dialects have surfaced. While there have been an extrinsic evaluation of these models with respect to downstream NLP tasks, no work has been carried out to analyze and compare their internal representations. We probe how linguistic information is encoded in the transformer models, trained on different Arabic dialects. We perform a layer and neuron analysis on the models using morphological tagging tasks for different dialects of Arabic and a dialectal identification task. Our analysis enlightens interesting findings such as: i) word morphology is learned at the lower and middle layers, ii) while syntactic dependencies are predominantly captured at the higher layers, iii) despite a large overlap in their vocabulary, the MSA-based models fail to capture the nuances of Arabic dialects, iv) we found that neurons in embedding layers are polysemous in nature, while the neurons in middle layers are exclusive to specific properties.",
}
NatiQ: An End-to-end Text-to-Speech System for Arabic
NatiQ is end-to-end text-to-speech system for Arabic. Our speech synthesizer uses an encoder-decoder architecture with attention. We used both tacotron-based models (tacotron- 1 and tacotron-2) and the faster transformer model for generating mel-spectrograms from characters. We concatenated Tacotron1 with the WaveRNN vocoder, Tacotron2 with the WaveGlow vocoder and ESPnet transformer with the parallel wavegan vocoder to synthesize waveforms from the spectrograms. We used in-house speech data for two voices: 1) neu- tral male {``}Hamza{''}- narrating general content and news, and 2) expressive female {``}Amina{''}- narrating children story books to train our models. Our best systems achieve an aver- age Mean Opinion Score (MOS) of 4.21 and 4.40 for Amina and Hamza respectively. The objective evaluation of the systems using word and character error rate (WER and CER) as well as the response time measured by real- time factor favored the end-to-end architecture ESPnet. NatiQ demo is available online at https://tts.qcri.org.
@inproceedings{abdelali-etal-2022-natiq,
title = "{N}ati{Q}: An End-to-end Text-to-Speech System for {A}rabic",
author = "Abdelali, Ahmed and
Durrani, Nadir and
Demiroglu, Cenk and
Dalvi, Fahim and
Mubarak, Hamdy and
Darwish, Kareem",
booktitle = "Proceedings of the The Seventh Arabic Natural Language Processing Workshop (WANLP)",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates (Hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.wanlp-1.38",
doi = "10.18653/v1/2022.wanlp-1.38",
pages = "394--398",
abstract = "NatiQ is end-to-end text-to-speech system for Arabic. Our speech synthesizer uses an encoder-decoder architecture with attention. We used both tacotron-based models (tacotron- 1 and tacotron-2) and the faster transformer model for generating mel-spectrograms from characters. We concatenated Tacotron1 with the WaveRNN vocoder, Tacotron2 with the WaveGlow vocoder and ESPnet transformer with the parallel wavegan vocoder to synthesize waveforms from the spectrograms. We used in-house speech data for two voices: 1) neu- tral male {``}Hamza{''}- narrating general content and news, and 2) expressive female {``}Amina{''}- narrating children story books to train our models. Our best systems achieve an aver- age Mean Opinion Score (MOS) of 4.21 and 4.40 for Amina and Hamza respectively. The objective evaluation of the systems using word and character error rate (WER and CER) as well as the response time measured by real- time factor favored the end-to-end architecture ESPnet. NatiQ demo is available online at https://tts.qcri.org.",
}
Neuron-level Interpretation of Deep NLP Models: A Survey
The proliferation of Deep Neural Networks in various domains has seen an increased need for interpretability of these models. Preliminary work done along this line, and papers that surveyed such, are focused on high-level representation analysis. However, a recent branch of work has concentrated on interpretability at a more granular level of analyzing neurons within these models. In this paper, we survey the work done on neuron analysis including: i) methods to discover and understand neurons in a network; ii) evaluation methods; iii) major findings including cross architectural comparisons that neuron analysis has unraveled; iv) applications of neuron probing such as: controlling the model, domain adaptation, and so forth; and v) a discussion on open issues and future research directions.
@article{sajjad-etal-2022-neuron,
title = "Neuron-level Interpretation of Deep {NLP} Models: A Survey",
author = "Sajjad, Hassan and
Durrani, Nadir and
Dalvi, Fahim",
journal = "Transactions of the Association for Computational Linguistics",
volume = "10",
year = "2022",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/2022.tacl-1.74",
doi = "10.1162/tacl_a_00519",
pages = "1285--1303",
abstract = "The proliferation of Deep Neural Networks in various domains has seen an increased need for interpretability of these models. Preliminary work done along this line, and papers that surveyed such, are focused on high-level representation analysis. However, a recent branch of work has concentrated on interpretability at a more granular level of analyzing neurons within these models. In this paper, we survey the work done on neuron analysis including: i) methods to discover and understand neurons in a network; ii) evaluation methods; iii) major findings including cross architectural comparisons that neuron analysis has unraveled; iv) applications of neuron probing such as: controlling the model, domain adaptation, and so forth; and v) a discussion on open issues and future research directions.",
}

Effect of Post-processing on Contextualized Word Representations
Post-processing of static embedding has been shown to improve their performance on both lexical and sequence-level tasks. However, post-processing for contextualized embeddings is an under-studied problem. In this work, we question the usefulness of post-processing for contextualized embeddings obtained from different layers of pre-trained language models. More specifically, we standardize individual neuron activations using z-score, min-max normalization, and by removing top principal components using the all-but-the-top method. Additionally, we apply unit length normalization to word representations. On a diverse set of pre-trained models, we show that post-processing unwraps vital information present in the representations for both lexical tasks (such as word similarity and analogy) and sequence classification tasks. Our findings raise interesting points in relation to the research studies that use contextualized representations, and suggest z-score normalization as an essential step to consider when using them in an application.
@inproceedings{sajjad-etal-2022-effect,
title = "Effect of Post-processing on Contextualized Word Representations",
author = "Sajjad, Hassan and
Alam, Firoj and
Dalvi, Fahim and
Durrani, Nadir",
booktitle = "Proceedings of the 29th International Conference on Computational Linguistics",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2022.coling-1.277",
pages = "3127--3142",
abstract = "Post-processing of static embedding has been shown to improve their performance on both lexical and sequence-level tasks. However, post-processing for contextualized embeddings is an under-studied problem. In this work, we question the usefulness of post-processing for contextualized embeddings obtained from different layers of pre-trained language models. More specifically, we standardize individual neuron activations using z-score, min-max normalization, and by removing top principal components using the all-but-the-top method. Additionally, we apply unit length normalization to word representations. On a diverse set of pre-trained models, we show that post-processing unwraps vital information present in the representations for both lexical tasks (such as word similarity and analogy) and sequence classification tasks. Our findings raise interesting points in relation to the research studies that use contextualized representations, and suggest z-score normalization as an essential step to consider when using them in an application.",
}
Analyzing Encoded Concepts in Transformer Language Models
We propose a novel framework ConceptX, to analyze how latent concepts are encoded in representations learned within pre-trained lan-guage models. It uses clustering to discover the encoded concepts and explains them by aligning with a large set of human-defined concepts. Our analysis on seven transformer language models reveal interesting insights: i) the latent space within the learned representations overlap with different linguistic concepts to a varying degree, ii) the lower layers in the model are dominated by lexical concepts (e.g., affixation) and linguistic ontologies (e.g. Word-Net), whereas the core-linguistic concepts (e.g., morphology, syntactic relations) are better represented in the middle and higher layers, iii) some encoded concepts are multi-faceted and cannot be adequately explained using the existing human-defined concepts.
@inproceedings{sajjad-etal-2022-analyzing,
title = "Analyzing Encoded Concepts in Transformer Language Models",
author = "Sajjad, Hassan and
Durrani, Nadir and
Dalvi, Fahim and
Alam, Firoj and
Khan, Abdul and
Xu, Jia",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.225",
doi = "10.18653/v1/2022.naacl-main.225",
pages = "3082--3101",
abstract = "We propose a novel framework ConceptX, to analyze how latent concepts are encoded in representations learned within pre-trained lan-guage models. It uses clustering to discover the encoded concepts and explains them by aligning with a large set of human-defined concepts. Our analysis on seven transformer language models reveal interesting insights: i) the latent space within the learned representations overlap with different linguistic concepts to a varying degree, ii) the lower layers in the model are dominated by lexical concepts (e.g., affixation) and linguistic ontologies (e.g. Word-Net), whereas the core-linguistic concepts (e.g., morphology, syntactic relations) are better represented in the middle and higher layers, iii) some encoded concepts are multi-faceted and cannot be adequately explained using the existing human-defined concepts.",
}
Discovering Latent Concepts Learned in BERT
A large number of studies that analyze deep neural network models and their ability to encode various linguistic and non-linguistic concepts provide an interpretation of the inner mechanics of these models. The scope of the analyses is limited to pre-defined concepts that reinforce the traditional linguistic knowledge and do not reflect on how novel concepts are learned by the model. We address this limitation by discovering and analyzing latent concepts learned in neural network models in an unsupervised fashion and provide interpretations from the model's perspective. In this work, we study: i) what latent concepts exist in the pre-trained BERT model, ii) how the discovered latent concepts align or diverge from classical linguistic hierarchy and iii) how the latent concepts evolve across layers. Our findings show: i) a model learns novel concepts (e.g. animal categories and demographic groups), which do not strictly adhere to any pre-defined categorization (e.g. POS, semantic tags), ii) several latent concepts are based on multiple properties which may include semantics, syntax, and morphology, iii) the lower layers in the model dominate in learning shallow lexical concepts while the higher layers learn semantic relations and iv) the discovered latent concepts highlight potential biases learned in the model. We also release a novel BERT ConceptNet dataset consisting of 174 concept labels and 1M annotated instances.
@inproceedings{
dalvi2022discovering,
title={Discovering Latent Concepts Learned in {BERT}},
author={Fahim Dalvi
and Abdul Rafae Khan
and Firoj Alam
and Nadir Durrani
and Jia Xu
and Hassan Sajjad},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=POTMtpYI1xH}
}
2021

Fighting the COVID-19 Infodemic: Modeling the Perspective of Journalists, Fact-Checkers, Social Media Platforms, Policy Makers, and the Society
With the emergence of the COVID-19 pandemic, the political and the medical aspects of disinformation merged as the problem got elevated to a whole new level to become the first global infodemic. Fighting this infodemic has been declared one of the most important focus areas of the World Health Organization, with dangers ranging from promoting fake cures, rumors, and conspiracy theories to spreading xenophobia and panic. Addressing the issue requires solving a number of challenging problems such as identifying messages containing claims, determining their check-worthiness and factuality, and their potential to do harm as well as the nature of that harm, to mention just a few. To address this gap, we release a large dataset of 16K manually annotated tweets for fine-grained disinformation analysis that (i) focuses on COVID-19, (ii) combines the perspectives and the interests of journalists, fact-checkers, social media platforms, policy makers, and society, and (iii) covers Arabic, Bulgarian, Dutch, and English. Finally, we show strong evaluation results using pretrained Transformers, thus confirming the practical utility of the dataset in monolingual vs. multilingual, and single task vs. multitask settings.
@inproceedings{alam-etal-2021-fighting-covid,
title = "Fighting the {COVID}-19 Infodemic: Modeling the Perspective of Journalists, Fact-Checkers, Social Media Platforms, Policy Makers, and the Society",
author = "Alam, Firoj and
Shaar, Shaden and
Dalvi, Fahim and
Sajjad, Hassan and
Nikolov, Alex and
Mubarak, Hamdy and
Da San Martino, Giovanni and
Abdelali, Ahmed and
Durrani, Nadir and
Darwish, Kareem and
Al-Homaid, Abdulaziz and
Zaghouani, Wajdi and
Caselli, Tommaso and
Danoe, Gijs and
Stolk, Friso and
Bruntink, Britt and
Nakov, Preslav",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-emnlp.56",
doi = "10.18653/v1/2021.findings-emnlp.56",
pages = "611--649",
abstract = "With the emergence of the COVID-19 pandemic, the political and the medical aspects of disinformation merged as the problem got elevated to a whole new level to become the first global infodemic. Fighting this infodemic has been declared one of the most important focus areas of the World Health Organization, with dangers ranging from promoting fake cures, rumors, and conspiracy theories to spreading xenophobia and panic. Addressing the issue requires solving a number of challenging problems such as identifying messages containing claims, determining their check-worthiness and factuality, and their potential to do harm as well as the nature of that harm, to mention just a few. To address this gap, we release a large dataset of 16K manually annotated tweets for fine-grained disinformation analysis that (i) focuses on COVID-19, (ii) combines the perspectives and the interests of journalists, fact-checkers, social media platforms, policy makers, and society, and (iii) covers Arabic, Bulgarian, Dutch, and English. Finally, we show strong evaluation results using pretrained Transformers, thus confirming the practical utility of the dataset in monolingual vs. multilingual, and single task vs. multitask settings.",
}
How transfer learning impacts linguistic knowledge in deep NLP models?
Transfer learning from pre-trained neural language models towards downstream tasks has been a predominant theme in NLP recently. Several researchers have shown that deep NLP models learn non-trivial amount of linguistic knowledge, captured at different layers of the model. We investigate how fine-tuning towards downstream NLP tasks impacts the learned linguistic knowledge. We carry out a study across popular pre-trained models BERT, RoBERTa and XLNet using layer and neuron-level diagnostic classifiers. We found that for some GLUE tasks, the network relies on the core linguistic information and preserve it deeper in the network, while for others it forgets. Linguistic information is distributed in the pre-trained language models but becomes localized to the lower layers post-fine-tuning, reserving higher layers for the task specific knowledge. The pattern varies across architectures, with BERT retaining linguistic information relatively deeper in the network compared to RoBERTa and XLNet, where it is predominantly delegated to the lower layers.
@inproceedings{durrani-etal-2021-transfer,
title = "How transfer learning impacts linguistic knowledge in deep {NLP} models?",
author = "Durrani, Nadir and
Sajjad, Hassan and
Dalvi, Fahim",
booktitle = "Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-acl.438",
doi = "10.18653/v1/2021.findings-acl.438",
pages = "4947--4957",
}
Fighting the COVID-19 Infodemic in Social Media: A Holistic Perspective and a Call to Arms
With the outbreak of the COVID-19 pandemic, people turned to social media to read and to share timely information including statistics, warnings, advice, and inspirational stories. Unfortunately, alongside all this useful information, there was also a new blending of medical and political misinformation and disinformation, which gave rise to the first global infodemic. While fighting this infodemic is typically thought of in terms of factuality, the problem is much broader as malicious content includes not only fake news, rumors, and conspiracy theories, but also promotion of fake cures, panic, racism, xenophobia, and mistrust in the authorities, among others. This is a complex problem that needs a holistic approach combining the perspectives of journalists, fact-checkers, policymakers, government entities, social media platforms, and society as a whole. With this in mind, we define an annotation schema and detailed annotation instructions that reflect these perspectives. We further deploy a multilingual annotation platform, and we issue a call to arms to the research community and beyond to join the fight by supporting our crowdsourcing annotation efforts. We perform initial annotations using the annotation schema, and our initial experiments demonstrated sizable improvements over the baselines.
@article{Alam_covid_infodemic_2021,
title={Fighting the COVID-19 Infodemic in Social Media: A Holistic Perspective and a Call to Arms},
author={Alam, Firoj and Dalvi, Fahim and Shaar, Shaden and Durrani, Nadir and Mubarak, Hamdy and Nikolov, Alex and Da San Martino, Giovanni and Abdelali, Ahmed and Sajjad, Hassan and Darwish, Kareem and Nakov, Preslav},
volume={15},
url={https://ojs.aaai.org/index.php/ICWSM/article/view/18114},
number={1},
journal={Proceedings of the International AAAI Conference on Web and Social Media},
year={2021},
month={May},
pages={913-922},
abstractNote={With the outbreak of the COVID-19 pandemic, people turned to social media to read and to share timely information including statistics, warnings, advice, and inspirational stories. Unfortunately, alongside all this useful information, there was also a new blending of medical and political misinformation and disinformation, which gave rise to the first global infodemic. While fighting this infodemic is typically thought of in terms of factuality, the problem is much broader as malicious content includes not only fake news, rumors, and conspiracy theories, but also promotion of fake cures, panic, racism, xenophobia, and mistrust in the authorities, among others. This is a complex problem that needs a holistic approach combining the perspectives of journalists, fact-checkers, policymakers, government entities, social media platforms, and society as a whole. With this in mind, we define an annotation schema and detailed annotation instructions that reflect these perspectives. We further deploy a multilingual annotation platform, and we issue a call to arms to the research community and beyond to join the fight by supporting our crowdsourcing annotation efforts. We perform initial annotations using the annotation schema, and our initial experiments demonstrated sizable improvements over the baselines.}
}
Fine-grained Interpretation and Causation Analysis in Deep NLP Models
Deep neural networks have constantly pushed the state-of-the-art performance in natural language processing and are considered as the de-facto modeling approach in solving complex NLP tasks such as machine translation, summarization and question-answering. Despite the proven efficacy of deep neural networks at-large, their opaqueness is a major cause of concern. In this tutorial, we will present research work on interpreting fine-grained components of a neural network model from two perspectives, i) fine-grained interpretation, and ii) causation analysis. The former is a class of methods to analyze neurons with respect to a desired language concept or a task. The latter studies the role of neurons and input features in explaining the decisions made by the model. We will also discuss how interpretation methods and causation analysis can connect towards better interpretability of model prediction. Finally, we will walk you through various toolkits that facilitate fine-grained interpretation and causation analysis of neural models.
@inproceedings{sajjad-etal-2021-fine,
title = "Fine-grained Interpretation and Causation Analysis in Deep {NLP} Models",
author = "Sajjad, Hassan and
Kokhlikyan, Narine and
Dalvi, Fahim and
Durrani, Nadir",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Tutorials",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.naacl-tutorials.2",
pages = "5--10",
abstract = "Deep neural networks have constantly pushed the state-of-the-art performance in natural language processing and are considered as the de-facto modeling approach in solving complex NLP tasks such as machine translation, summarization and question-answering. Despite the proven efficacy of deep neural networks at-large, their opaqueness is a major cause of concern. In this tutorial, we will present research work on interpreting fine-grained components of a neural network model from two perspectives, i) fine-grained interpretation, and ii) causation analysis. The former is a class of methods to analyze neurons with respect to a desired language concept or a task. The latter studies the role of neurons and input features in explaining the decisions made by the model. We will also discuss how interpretation methods and causation analysis can connect towards better interpretability of model prediction. Finally, we will walk you through various toolkits that facilitate fine-grained interpretation and causation analysis of neural models.",
}2020

AraBench: Benchmarking Dialectal Arabic-English Machine Translation
Low-resource machine translation suffers from the scarcity of training data and the unavailability of standard evaluation sets. While a number of research efforts target the former, the unavailability of evaluation benchmarks remain a major hindrance in tracking the progress in low-resource machine translation. In this paper, we introduce AraBench, an evaluation suite for dialectal Arabic to English machine translation. Compared to Modern Standard Arabic, Arabic dialects are challenging due to their spoken nature, non-standard orthography, and a large variation in dialectness. To this end, we pool together already available Dialectal Arabic-English resources and additionally build novel test sets. AraBench offers 4 coarse, 15 fine-grained and 25 city-level dialect categories, belonging to diverse genres, such as media, chat, religion and travel with varying level of dialectness. We report strong baselines using several training settings: fine-tuning, back-translation and data augmentation. The evaluation suite opens a wide range of research frontiers to push efforts in low-resource machine translation, particularly Arabic dialect translation. The evaluation suite and the dialectal system are publicly available for research purposes.
@inproceedings{sajjad-etal-2020-arabench,
title = "{A}ra{B}ench: Benchmarking Dialectal {A}rabic-{E}nglish Machine Translation",
author = "Sajjad, Hassan and
Abdelali, Ahmed and
Durrani, Nadir and
Dalvi, Fahim",
booktitle = "Proceedings of the 28th International Conference on Computational Linguistics",
month = dec,
year = "2020",
address = "Barcelona, Spain (Online)",
publisher = "International Committee on Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.coling-main.447",
doi = "10.18653/v1/2020.coling-main.447",
pages = "5094--5107",
abstract = "Low-resource machine translation suffers from the scarcity of training data and the unavailability of standard evaluation sets. While a number of research efforts target the former, the unavailability of evaluation benchmarks remain a major hindrance in tracking the progress in low-resource machine translation. In this paper, we introduce AraBench, an evaluation suite for dialectal Arabic to English machine translation. Compared to Modern Standard Arabic, Arabic dialects are challenging due to their spoken nature, non-standard orthography, and a large variation in dialectness. To this end, we pool together already available Dialectal Arabic-English resources and additionally build novel test sets. AraBench offers 4 coarse, 15 fine-grained and 25 city-level dialect categories, belonging to diverse genres, such as media, chat, religion and travel with varying level of dialectness. We report strong baselines using several training settings: fine-tuning, back-translation and data augmentation. The evaluation suite opens a wide range of research frontiers to push efforts in low-resource machine translation, particularly Arabic dialect translation. The evaluation suite and the dialectal system are publicly available for research purposes.",
}

Analyzing Individual Neurons in Pre-trained Language Models
While a lot of analysis has been carried to demonstrate linguistic knowledge captured by the representations learned within deep NLP models, very little attention has been paid towards individual neurons. We carry out a neuron-level analysis using core linguistic tasks of predicting morphology, syntax and semantics, on pre-trained language models, with questions like: i) do individual neurons in pretrained models capture linguistic information? ii) which parts of the network learn more about certain linguistic phenomena? iii) how distributed or focused is the information? and iv) how do various architectures differ in learning these properties? We found small subsets of neurons to predict linguistic tasks, with lower level tasks (such as morphology) localized in fewer neurons, compared to higher level task of predicting syntax. Our study reveals interesting cross architectural comparisons. For example, we found neurons in XLNet to be more localized and disjoint when predicting properties compared to BERT and others, where they are more distributed and coupled.
@inproceedings{durrani-etal-2020-analyzing,
title = "Analyzing Individual Neurons in Pre-trained Language Models",
author = "Durrani, Nadir and
Sajjad, Hassan and
Dalvi, Fahim and
Belinkov, Yonatan",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.395",
doi = "10.18653/v1/2020.emnlp-main.395",
pages = "4865--4880",
abstract = "While a lot of analysis has been carried to demonstrate linguistic knowledge captured by the representations learned within deep NLP models, very little attention has been paid towards individual neurons.We carry outa neuron-level analysis using core linguistic tasks of predicting morphology, syntax and semantics, on pre-trained language models, with questions like: i) do individual neurons in pre-trained models capture linguistic information? ii) which parts of the network learn more about certain linguistic phenomena? iii) how distributed or focused is the information? and iv) how do various architectures differ in learning these properties? We found small subsets of neurons to predict linguistic tasks, with lower level tasks (such as morphology) localized in fewer neurons, compared to higher level task of predicting syntax. Our study also reveals interesting cross architectural comparisons. For example, we found neurons in XLNet to be more localized and disjoint when predicting properties compared to BERT and others, where they are more distributed and coupled.",
}

Analyzing Redundancy in Pretrained Transformer Models
Transformer-based deep NLP models are trained using hundreds of millions of parameters, limiting their applicability in computationally constrained environments. In this paper, we study the cause of these limitations by defining a notion of Redundancy, which we categorize into two classes: General Redundancy and Task-specific Redundancy. We dissect two popular pretrained models, BERT and XLNet, studying how much redundancy they exhibit at a representation-level and at a more fine-grained neuron-level. Our analysis reveals interesting insights, such as: i) 85% of the neurons across the network are redundant and ii) at least 92% of them can be removed when optimizing towards a downstream task. Based on our analysis, we present an efficient feature-based transfer learning procedure, which maintains 97% performance while using at-most 10% of the original neurons.
@inproceedings{dalvi-etal-2020-analyzing,
title = "Analyzing Redundancy in Pretrained Transformer Models",
author = "Dalvi, Fahim and
Sajjad, Hassan and
Durrani, Nadir and
Belinkov, Yonatan",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.398",
doi = "10.18653/v1/2020.emnlp-main.398",
pages = "4908--4926",
abstract = "Transformer-based deep NLP models are trained using hundreds of millions of parameters, limiting their applicability in computationally constrained environments. In this paper, we study the cause of these limitations by defining a notion of Redundancy, which we categorize into two classes: General Redundancy and Task-specific Redundancy. We dissect two popular pretrained models, BERT and XLNet, studying how much redundancy they exhibit at a representation-level and at a more fine-grained neuron-level. Our analysis reveals interesting insights, such as i) 85{\%} of the neurons across the network are redundant and ii) at least 92{\%} of them can be removed when optimizing towards a downstream task. Based on our analysis, we present an efficient feature-based transfer learning procedure, which maintains 97{\%} performance while using at-most 10{\%} of the original neurons.",
}
Similarity Analysis of Contextual Word Representation Models
This paper investigates contextual word representation models from the lens of similarity analysis. Given a collection of trained models, we measure the similarity of their internal representations and attention. Critically, these models come from vastly different architectures. We use existing and novel similarity measures that aim to gauge the level of localization of information in the deep models, and facilitate the investigation of which design factors affect model similarity, without requiring any external linguistic annotation. The analysis reveals that models within the same family are more similar to one another, as may be expected. Surprisingly, different architectures have rather similar representations, but different individual neurons. We also observed differences in information localization in lower and higher layers and found that higher layers are more affected by fine-tuning on downstream tasks.
@inproceedings{wu-etal-2020-similarity,
title = "Similarity Analysis of Contextual Word Representation Models",
author = "Wu, John and
Belinkov, Yonatan and
Sajjad, Hassan and
Durrani, Nadir and
Dalvi, Fahim and
Glass, James",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.422",
doi = "10.18653/v1/2020.acl-main.422",
pages = "4638--4655",
abstract = "This paper investigates contextual word representation models from the lens of similarity analysis. Given a collection of trained models, we measure the similarity of their internal representations and attention. Critically, these models come from vastly different architectures. We use existing and novel similarity measures that aim to gauge the level of localization of information in the deep models, and facilitate the investigation of which design factors affect model similarity, without requiring any external linguistic annotation. The analysis reveals that models within the same family are more similar to one another, as may be expected. Surprisingly, different architectures have rather similar representations, but different individual neurons. We also observed differences in information localization in lower and higher layers and found that higher layers are more affected by fine-tuning on downstream tasks.",
}
On the Linguistic Representational Power of Neural Machine Translation Models
Despite the recent success of deep neural networks in natural language processing and other spheres of artificial intelligence, their interpretability remains a challenge. We analyze the representations learned by neural machine translation (NMT) models at various levels of granularity and evaluate their quality through relevant extrinsic properties. In particular, we seek answers to the following questions: (i) How accurately is word structure captured within the learned representations, which is an important aspect in translating morphologically rich languages? (ii) Do the representations capture long-range dependencies, and effectively handle syntactically divergent languages? (iii) Do the representations capture lexical semantics? We conduct a thorough investigation along several parameters: (i) Which layers in the architecture capture each of these linguistic phenomena; (ii) How does the choice of translation unit (word, character, or subword unit) impact the linguistic properties captured by the underlying representations? (iii) Do the encoder and decoder learn differently and independently? (iv) Do the representations learned by multilingual NMT models capture the same amount of linguistic information as their bilingual counterparts? Our data-driven, quantitative evaluation illuminates important aspects in NMT models and their ability to capture various linguistic phenomena. We show that deep NMT models trained in an end-to-end fashion, without being provided any direct supervision during the training process, learn a non-trivial amount of linguistic information. Notable findings include the following observations: (i) Word morphology and part-of-speech information are captured at the lower layers of the model; (ii) In contrast, lexical semantics or non-local syntactic and semantic dependencies are better represented at the higher layers of the model; (iii) Representations learned using characters are more informed about word-morphology compared to those learned using subword units; and (iv) Representations learned by multilingual models are richer compared to bilingual models.
@article{belinkov-etal-2020-linguistic,
title = "On the Linguistic Representational Power of Neural Machine Translation Models",
author = "Belinkov, Yonatan and
Durrani, Nadir and
Dalvi, Fahim and
Sajjad, Hassan and
Glass, James",
journal = "Computational Linguistics",
volume = "46",
number = "1",
month = mar,
year = "2020",
url = "https://www.aclweb.org/anthology/2020.cl-1.1",
doi = "10.1162/coli_a_00367",
pages = "1--52"
}
2019

Rumour verification through recurring information and an inner-attention mechanism
Verification of online rumours is becoming an increasingly important task with the prevalence of event discussions on social media platforms. This paper proposes an inner-attention-based neural network model that uses frequent, recurring terms from past rumours to classify a newly emerging rumour as true, false or unverified. Unlike other methods proposed in related work, our model uses the source rumour alone without any additional information, such as user replies to the rumour or additional feature engineering. Our method outperforms the current state-of-the-art methods on benchmark datasets (RumourEval2017) by 3% accuracy and 6% F-1 leading to 60.7% accuracy and 61.6% F-1. We also compare our attention-based method to two similar models which however do not make use of recurrent terms. The attention-based method guided by frequent recurring terms outperforms this baseline on the same dataset, indicating that the recurring terms injected by the attention mechanism have high positive impact on distinguishing between true and false rumours. Furthermore, we perform out-of-domain evaluations and show that our model is indeed highly competitive compared to the baselines on a newly released RumourEval2019 dataset and also achieves the best performance on classifying fake and legitimate news headlines.
@article{AKER2019100045,
title = "Rumour verification through recurring information and an inner-attention mechanism",
journal = "Online Social Networks and Media",
volume = "13",
pages = "100045",
year = "2019",
issn = "2468-6964",
doi = "https://doi.org/10.1016/j.osnem.2019.07.001",
url = "http://www.sciencedirect.com/science/article/pii/S2468696419300588",
author = "Ahmet Aker and Alfred Sliwa and Fahim Dalvi and Kalina Bontcheva",
keywords = "Rumour Verification, Inner Attention Model, Recurring Terms in Rumours"
}
One Size Does Not Fit All: Comparing NMT Representations of Different Granularities
Recent work has shown that contextualized word representations derived from neural machine translation are a viable alternative to such from simple word predictions tasks. This is because the internal understanding that needs to be built in order to be able to translate from one language to another is much more comprehensive. Unfortunately, computational and memory limitations as of present prevent NMT models from using large word vocabularies, and thus alternatives such as subword units (BPE and morphological segmentations) and characters have been used. Here we study the impact of using different kinds of units on the quality of the resulting representations when used to model morphology, syntax, and semantics. We found that while representations derived from subwords are slightly better for modeling syntax, character-based representations are superior for modeling morphology and are also more robust to noisy input.
@inproceedings{durrani-etal-2019-one,
title = "One Size Does Not Fit All: Comparing {NMT} Representations of Different Granularities",
author = "Durrani, Nadir and
Dalvi, Fahim and
Sajjad, Hassan and
Belinkov, Yonatan and
Nakov, Preslav",
booktitle = "Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers)",
month = jun,
year = "2019",
address = "Minneapolis, Minnesota",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/N19-1154",
doi = "10.18653/v1/N19-1154",
pages = "1504--1516",
abstract = "Recent work has shown that contextualized word representations derived from neural machine translation are a viable alternative to such from simple word predictions tasks. This is because the internal understanding that needs to be built in order to be able to translate from one language to another is much more comprehensive. Unfortunately, computational and memory limitations as of present prevent NMT models from using large word vocabularies, and thus alternatives such as subword units (BPE and morphological segmentations) and characters have been used. Here we study the impact of using different kinds of units on the quality of the resulting representations when used to model morphology, syntax, and semantics. We found that while representations derived from subwords are slightly better for modeling syntax, character-based representations are superior for modeling morphology and are also more robust to noisy input.",
}
Identifying And Controlling Important Neurons In Neural Machine Translation
Neural machine translation (NMT) models learn representations containing substantial linguistic information. However, it is not clear if such information is fully distributed or if some of it can be attributed to individual neurons. We develop unsupervised methods for discovering important neurons in NMT models. Our methods rely on the intuition that different models learn similar properties, and do not require any costly external supervision. We show experimentally that translation quality depends on the discovered neurons, and find that many of them capture common linguistic phenomena. Finally, we show how to control NMT translations in predictable ways, by modifying activations of individual neurons.
@inproceedings{
bau2018identifying,
title={Identifying and Controlling Important Neurons in Neural Machine Translation},
author={Anthony Bau
and Yonatan Belinkov
and Hassan Sajjad
and Nadir Durrani
and Fahim Dalvi
and James Glass},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=H1z-PsR5KX},
}

What Is One Grain of Sand in the Desert? Analyzing Individual Neurons in Deep NLP Models
Despite the remarkable evolution of deep neural networks in natural language processing (NLP), their interpretability remains a challenge. Previous work largely focused on what these models learn at the representation level. We break this analysis down further and study individual dimensions (neurons) in the vector representation learned by end-to-end neural models in NLP tasks. We propose two methods: Linguistic Correlation Analysis, based on a supervised method to extract the most relevant neurons with respect to an extrinsic task, and Cross-model Correlation Analysis, an unsupervised method to extract salient neurons w.r.t. the model itself. We evaluate the effectiveness of our techniques by ablating the identified neurons and reevaluating the network’s performance for two tasks: neural machine translation (NMT) and neural language modeling (NLM). We further present a comprehensive analysis of neurons with the aim to address the following questions: i) how localized or distributed are different linguistic properties in the models? ii) are certain neurons exclusive to some properties and not others? iii) is the information more or less distributed in NMT vs. NLM? and iv) how important are the neurons identified through the linguistic correlation method to the overall task? Our code is publicly available as part of the NeuroX toolkit (Dalvi et al. 2019a). This paper is a non-archived version of the paper published at AAAI (Dalvi et al. 2019b).
@article{dalvi2019individualneurons,
title={What Is One Grain of Sand in the Desert? Analyzing Individual Neurons in Deep NLP Models},
author={Dalvi, Fahim and Durrani, Nadir and Sajjad, Hassan and Belinkov, Yonatan and Bau, Anthony and Glass, James},
volume={33},
url={https://ojs.aaai.org/index.php/AAAI/article/view/4592},
DOI={10.1609/aaai.v33i01.33016309},
number={01},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
year={2019},
month={Jul.},
pages={6309-6317},
abstractNote={Despite the remarkable evolution of deep neural networks in natural language processing (NLP), their interpretability remains a challenge. Previous work largely focused on what these models learn at the representation level. We break this analysis down further and study individual dimensions (neurons) in the vector representation learned by end-to-end neural models in NLP tasks. We propose two methods: <em>Linguistic Correlation Analysis</em>, based on a supervised method to extract the most relevant neurons with respect to an extrinsic task, and <em>Cross-model Correlation Analysis</em>, an unsupervised method to extract salient neurons w.r.t. the model itself. We evaluate the effectiveness of our techniques by ablating the identified neurons and reevaluating the network’s performance for two tasks: neural machine translation (NMT) and neural language modeling (NLM). We further present a comprehensive analysis of neurons with the aim to address the following questions: i) how localized or distributed are different linguistic properties in the models? ii) are certain neurons exclusive to some properties and not others? iii) is the information more or less distributed in NMT vs. NLM? and iv) how important are the neurons identified through the linguistic correlation method to the overall task? Our code is publicly available as part of the NeuroX toolkit (Dalvi et al. 2019a). This paper is a non-archived version of the paper published at AAAI (Dalvi et al. 2019b).}
}

NeuroX: A Toolkit for Analyzing Individual Neurons in Neural Networks
We present a toolkit to facilitate the interpretation and understanding of neural network models. The toolkit provides several methods to identify salient neurons with respect to the model itself or an external task. A user can visualize selected neurons, ablate them to measure their effect on the model accuracy, and manipulate them to control the behavior of the model at the test time. Such an analysis has a potential to serve as a springboard in various research directions, such as understanding the model, better architectural choices, model distillation and controlling data biases. The toolkit is available for download.
@article{dalvi2019neurox,
title={NeuroX: A Toolkit for Analyzing Individual Neurons in Neural Networks},
author={Dalvi, Fahim and Nortonsmith, Avery and Bau, Anthony and Belinkov, Yonatan and Sajjad, Hassan and Durrani, Nadir and Glass, James},
volume={33},
url={https://ojs.aaai.org/index.php/AAAI/article/view/5063},
DOI={10.1609/aaai.v33i01.33019851},
number={01},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
year={2019},
month={Jul.},
pages={9851-9852},
abstractNote={We present a toolkit to facilitate the interpretation and understanding of neural network models. The toolkit provides several methods to identify salient neurons with respect to the model itself or an external task. A user can visualize selected neurons, ablate them to measure their effect on the model accuracy, and manipulate them to control the behavior of the model at the test time. Such an analysis has a potential to serve as a springboard in various research directions, such as understanding the model, better architectural choices, model distillation and controlling data biases. The toolkit is available for download.}
}
2018

Group Identification in Crowded Environments Using Proximity Sensing
Children and elderly separating from their family members is a common phenomenon, especially in crowded environments. In order to avoid this problem, places like Disney World and pilgrimage officials have developed systems like wearable tags to determine groups or families. These tags require information about families to be entered manually, either by the users or the facility organizers. The information, if correct, can then be used to help identify and locate a lost person's group. Manually entering information is inefficient, and usually leads to either long waiting times during entry, or partial information entry within the tags. In this paper, we propose a system that uses proximity sensing to determine groups and families without any input or interaction with the user. In our system, each user is given a wearable device that keeps track of it's neighbors using bluetooth transmissions. The system then uses this proximity data to predict cliques that represent family members.
@InProceedings{shaar2018group,
title={Group Identification in Crowded Environments Using Proximity Sensing},
author={Shaar, Shaden and Razak, Saquib and Dalvi, Fahim and Moosavi, Syed Ali Hashim},
booktitle={43rd {IEEE} Conference on Local Computer Networks, {LCN} 2018, Chicago, IL, USA, October 1-4, 2018},
pages={319--322},
year={2018},
organization={IEEE},
url={https://doi.org/10.1109/LCN.2018.8638142},
doi={10.1109/LCN.2018.8638142}
}
Incremental Decoding and Training Methods for Simultaneous Translation in Neural Machine Translation
We address the problem of simultaneous translation by modifying the Neural MT decoder to operate with dynamically built encoder and attention. We propose a tunable agent which decides the best segmentation strategy for a userdefined BLEU loss and Average Proportion (AP) constraint. Our agent outperforms previously proposed Wait-if-diff and Wait-if-worse agents (Cho and Esipova, 2016) on BLEU with a lower latency. Secondly we proposed datadriven changes to Neural MT training to better match the incremental decoding framework.
@inproceedings{dalvi-etal-2018-incremental,
title = "Incremental Decoding and Training Methods for Simultaneous Translation in Neural Machine Translation",
author = "Dalvi, Fahim and
Durrani, Nadir and
Sajjad, Hassan and
Vogel, Stephan",
booktitle = "Proceedings of the 2018 Conference of the North {A}merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers)",
month = jun,
year = "2018",
address = "New Orleans, Louisiana",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/N18-2079",
doi = "10.18653/v1/N18-2079",
pages = "493--499",
abstract = "We address the problem of simultaneous translation by modifying the Neural MT decoder to operate with dynamically built encoder and attention. We propose a tunable agent which decides the best segmentation strategy for a user-defined BLEU loss and Average Proportion (AP) constraint. Our agent outperforms previously proposed Wait-if-diff and Wait-if-worse agents (Cho and Esipova, 2016) on BLEU with a lower latency. Secondly we proposed data-driven changes to Neural MT training to better match the incremental decoding framework.",
}

Qlusty: Quick and Dirty Generation of Event Videos from Written Media Coverage
Qlusty generates videos describing the coverage of the same event by different news outlets automatically. Throughout four modules it identifies events, de-duplicates notes, ranks according to coverage, and queries for images to generate an overview video. In this manuscript we present our preliminary models, including quantitative evaluations of the former two and a qualitative analysis of the latter two. The results show the potential for achieving our main aim: contributing in breaking the information bubble, so common in the current news landscape.
@article{barron2018qlusty,
title={Qlusty: Quick and Dirty Generation of Event Videos from Written Media Coverage.},
author={Barr{\'o}n-Cede{\~n}o, Alberto
and Da San Martino, Giovanni
and Zhang, Yifan
and Ali, Ahmed M
and Dalvi, Fahim},
journal={NewsIR@ ECIR},
volume={2079},
pages={27--32},
year={2018}
}2017

Neural Machine Translation Training in a Multi-Domain Scenario
In this paper, we explore alternative ways to train a neural machine translation system in a multi-domain scenario. We investigate data concatenation (with fine tuning), model stacking (multi-level fine tuning), data selection and weighted ensemble. Our findings show that the best translation quality can be achieved by building an initial system on a concatenation of available out-of-domain data and then fine-tuning it on in-domain data. Model stacking works best when training begins with the furthest out-of-domain data and the model is incrementally fine-tuned with the next furthest domain and so on. Data selection did not give the best results, but can be considered as a decent compromise between training time and translation quality. A weighted ensemble of different individual models performed better than data selection. It is beneficial in a scenario when there is no time for fine-tuning.
@inproceedings{sajjad2017iwslt,
title={Neural Machine Translation Training in a Multi-Domain Scenario},
author={Sajjad, Hassan and Durrani, Nadir and Dalvi, Fahim and Belinkov, Yonatan and Vogel, Stephan},
booktitle={International Workshop on Spoken Language Translation},
year={2017}
}

Continuous Space Reordering Models for Phrase-based MT
Bilingual sequence models improve phrase-based translation and reordering by overcoming phrasal independence assumption and handling long range reordering. However, due to data sparsity, these models often fall back to very small context sizes. This problem has been previously addressed by learning sequences over generalized representations such as POS tags or word clusters. In this paper, we explore an alternative based on neural network models. More concretely we train neuralized versions of lexicalized reordering and the operation sequence models using feed-forward neural network. Our results show improvements of up to 0.6 and 0.5 BLEU points on top of the baseline German→English and English→German systems. We also observed improvements compared to the systems that used POS tags and word clusters to train these models. Because we modify the bilingual corpus to integrate reordering operations, this allows us to also train a sequence-to-sequence neural MT model having explicit reordering triggers. Our motivation was to directly enable reordering information in the encoder-decoder framework, which otherwise relies solely on the attention model to handle long range reordering. We tried both coarser and fine-grained reordering operations. However, these experiments did not yield any improvements over the baseline Neural MT systems.
@inproceedings{durrani2017iwslt,
title={Continuous Space Reordering Models for Phrase-based MT},
author={Durrani, Nadir and Dalvi, Fahim},
booktitle={International Workshop on Spoken Language Translation},
year={2017}
}

Understanding and Improving Morphological Learning in the Neural Machine Translation Decoder
End-to-end training makes the neural machine translation (NMT) architecture simpler, yet elegant compared to traditional statistical machine translation (SMT). However, little is known about linguistic patterns of morphology, syntax and semantics learned during the training of NMT systems, and more importantly, which parts of the architecture are responsible for learning each of these phenomena. In this paper we i) analyze how much morphology an NMT decoder learns, and ii) investigate whether injecting target morphology into the decoder helps it produce better translations. To this end we present three methods: i) joint generation, ii) joint-data learning, and iii) multi-task learning. Our results show that explicit morphological information helps the decoder learn target language morphology and improves the translation quality by 0.2–0.6 BLEU points.
@inproceedings{dalvi-etal-2017-understanding,
title = "Understanding and Improving Morphological Learning in the Neural Machine Translation Decoder",
author = "Dalvi, Fahim and
Durrani, Nadir and
Sajjad, Hassan and
Belinkov, Yonatan and
Vogel, Stephan",
booktitle = "Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = nov,
year = "2017",
address = "Taipei, Taiwan",
publisher = "Asian Federation of Natural Language Processing",
url = "https://www.aclweb.org/anthology/I17-1015",
pages = "142--151",
abstract = "End-to-end training makes the neural machine translation (NMT) architecture simpler, yet elegant compared to traditional statistical machine translation (SMT). However, little is known about linguistic patterns of morphology, syntax and semantics learned during the training of NMT systems, and more importantly, which parts of the architecture are responsible for learning each of these phenomenon. In this paper we i) analyze how much morphology an NMT decoder learns, and ii) investigate whether injecting target morphology in the decoder helps it to produce better translations. To this end we present three methods: i) simultaneous translation, ii) joint-data learning, and iii) multi-task learning. Our results show that explicit morphological information helps the decoder learn target language morphology and improves the translation quality by 0.2{--}0.6 BLEU points.",
}

Evaluating Layers of Representation in Neural Machine Translation on Part-of-Speech and Semantic Tagging Tasks
While neural machine translation (NMT) models provide improved translation quality in an elegant framework, it is less clear what they learn about language. Recent work has started evaluating the quality of vector representations learned by NMT models on morphological and syntactic tasks. In this paper, we investigate the representations learned at different layers of NMT encoders. We train NMT systems on parallel data and use the models to extract features for training a classifier on two tasks: part-of-speech and semantic tagging. We then measure the performance of the classifier as a proxy to the quality of the original NMT model for the given task. Our quantitative analysis yields interesting insights regarding representation learning in NMT models. For instance, we find that higher layers are better at learning semantics while lower layers tend to be better for part-of-speech tagging. We also observe little effect of the target language on source-side representations, especially in higher quality models.
@inproceedings{belinkov-etal-2017-evaluating,
title = "Evaluating Layers of Representation in Neural Machine Translation on Part-of-Speech and Semantic Tagging Tasks",
author = "Belinkov, Yonatan and
M{\`a}rquez, Llu{\'\i}s and
Sajjad, Hassan and
Durrani, Nadir and
Dalvi, Fahim and
Glass, James",
booktitle = "Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = nov,
year = "2017",
address = "Taipei, Taiwan",
publisher = "Asian Federation of Natural Language Processing",
url = "https://www.aclweb.org/anthology/I17-1001",
pages = "1--10",
abstract = "While neural machine translation (NMT) models provide improved translation quality in an elegant framework, it is less clear what they learn about language. Recent work has started evaluating the quality of vector representations learned by NMT models on morphological and syntactic tasks. In this paper, we investigate the representations learned at different layers of NMT encoders. We train NMT systems on parallel data and use the models to extract features for training a classifier on two tasks: part-of-speech and semantic tagging. We then measure the performance of the classifier as a proxy to the quality of the original NMT model for the given task. Our quantitative analysis yields interesting insights regarding representation learning in NMT models. For instance, we find that higher layers are better at learning semantics while lower layers tend to be better for part-of-speech tagging. We also observe little effect of the target language on source-side representations, especially in higher quality models.",
}

Challenging Language-Dependent Segmentation for Arabic: An Application to Machine Translation and Part-of-Speech Tagging
Word segmentation plays a pivotal role in improving any Arabic NLP application. Therefore, a lot of research has been spent in improving its accuracy. Off-the-shelf tools, however, are: i) complicated to use and ii) domain/dialect dependent. We explore three language-independent alternatives to morphological segmentation using: i) data-driven sub-word units, ii) characters as a unit of learning, and iii) word embeddings learned using a character CNN (Convolution Neural Network). On the tasks of Machine Translation and POS tagging, we found these methods to achieve close to, and occasionally surpass state-of-the-art performance. In our analysis, we show that a neural machine translation system is sensitive to the ratio of source and target tokens, and a ratio close to 1 or greater, gives optimal performance.
@inproceedings{sajjad-etal-2017-challenging,
title = "Challenging Language-Dependent Segmentation for {A}rabic: An Application to Machine Translation and Part-of-Speech Tagging",
author = "Sajjad, Hassan and
Dalvi, Fahim and
Durrani, Nadir and
Abdelali, Ahmed and
Belinkov, Yonatan and
Vogel, Stephan",
booktitle = "Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)",
month = jul,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P17-2095",
doi = "10.18653/v1/P17-2095",
pages = "601--607",
abstract = "Word segmentation plays a pivotal role in improving any Arabic NLP application. Therefore, a lot of research has been spent in improving its accuracy. Off-the-shelf tools, however, are: i) complicated to use and ii) domain/dialect dependent. We explore three language-independent alternatives to morphological segmentation using: i) data-driven sub-word units, ii) characters as a unit of learning, and iii) word embeddings learned using a character CNN (Convolution Neural Network). On the tasks of Machine Translation and POS tagging, we found these methods to achieve close to, and occasionally surpass state-of-the-art performance. In our analysis, we show that a neural machine translation system is sensitive to the ratio of source and target tokens, and a ratio close to 1 or greater, gives optimal performance.",
}
What do Neural Machine Translation Models Learn about Morphology?
Neural machine translation (MT) models obtain state-of-the-art performance while maintaining a simple, end-to-end architecture. However, little is known about what these models learn about source and target languages during the training process. In this work, we analyze the representations learned by neural MT models at various levels of granularity and empirically evaluate the quality of the representations for learning morphology through extrinsic part-of-speech and morphological tagging tasks. We conduct a thorough investigation along several parameters: word-based vs. character-based representations, depth of the encoding layer, the identity of the target language, and encoder vs. decoder representations. Our data-driven, quantitative evaluation sheds light on important aspects in the neural MT system and its ability to capture word structure.
@inproceedings{belinkov-etal-2017-neural,
title = "What do Neural Machine Translation Models Learn about Morphology?",
author = "Belinkov, Yonatan and
Durrani, Nadir and
Dalvi, Fahim and
Sajjad, Hassan and
Glass, James",
booktitle = "Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P17-1080",
doi = "10.18653/v1/P17-1080",
pages = "861--872",
abstract = "Neural machine translation (MT) models obtain state-of-the-art performance while maintaining a simple, end-to-end architecture. However, little is known about what these models learn about source and target languages during the training process. In this work, we analyze the representations learned by neural MT models at various levels of granularity and empirically evaluate the quality of the representations for learning morphology through extrinsic part-of-speech and morphological tagging tasks. We conduct a thorough investigation along several parameters: word-based vs. character-based representations, depth of the encoding layer, the identity of the target language, and encoder vs. decoder representations. Our data-driven, quantitative evaluation sheds light on important aspects in the neural MT system and its ability to capture word structure.",
}

QCRI's Live Speech Translation System
We present QCRI’s Arabic-to-English speech translation system. It features modern web technologies to capture live audio, and broadcasts Arabic transcriptions and English translations simultaneously. Our Kaldi-based ASR system uses the Time Delay Neural Network architecture, while our Machine Translation (MT) system uses both phrase-based and neural frameworks. Although our neural MT system is slower than the phrase-based system, it produces significantly better translations and is memory efficient.
@inproceedings{dalvi-etal-2017-qcri,
title = "{QCRI} Live Speech Translation System",
author = "Dalvi, Fahim and
Zhang, Yifan and
Khurana, Sameer and
Durrani, Nadir and
Sajjad, Hassan and
Abdelali, Ahmed and
Mubarak, Hamdy and
Ali, Ahmed and
Vogel, Stephan",
booktitle = "Proceedings of the Software Demonstrations of the 15th Conference of the {E}uropean Chapter of the Association for Computational Linguistics",
month = apr,
year = "2017",
address = "Valencia, Spain",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/E17-3016",
pages = "61--64",
abstract = "This paper presents QCRI{'}s Arabic-to-English live speech translation system. It features modern web technologies to capture live audio, and broadcasts Arabic transcriptions and English translations simultaneously. Our Kaldi-based ASR system uses the Time Delay Neural Network (TDNN) architecture, while our Machine Translation (MT) system uses both phrase-based and neural frameworks. Although our neural MT system is slower than the phrase-based system, it produces significantly better translations and is memory efficient. The demo is available at \url{https://st.qcri.org/demos/livetranslation}.",
}
2016

QCRI @ DSL 2016: Spoken Arabic Dialect Identification Using Textual Features
The paper describes the QCRI submissions to the shared task of automatic Arabic dialect classification into 5 Arabic variants, namely Egyptian, Gulf, Levantine, North-African (Maghrebi), and Modern Standard Arabic (MSA). The relatively small training set is automatically generated from an ASR system. To avoid over-fitting on such small data, we selected and designed features that capture the morphological essence of the different dialects. We submitted four runs to the Arabic sub-task. For all runs, we used a combined feature vector of character bigrams, trigrams, 4-grams, and 5-grams. We tried several machine-learning algorithms, namely Logistic Regres- sion, Naive Bayes, Neural Networks, and Support Vector Machines (SVM) with linear and string kernels. Our submitted runs used SVM with a linear kernel. In the closed submission, we got the best accuracy of 0.5136 and the third best weighted F1 score, with a difference of less than 0.002 from the best system.
@inproceedings{eldesouki-etal-2016-qcri,
title = "{QCRI} @ {DSL} 2016: Spoken {A}rabic Dialect Identification Using Textual Features",
author = "Eldesouki, Mohamed and
Dalvi, Fahim and
Sajjad, Hassan and
Darwish, Kareem",
booktitle = "Proceedings of the Third Workshop on {NLP} for Similar Languages, Varieties and Dialects ({V}ar{D}ial3)",
month = dec,
year = "2016",
address = "Osaka, Japan",
publisher = "The COLING 2016 Organizing Committee",
url = "https://www.aclweb.org/anthology/W16-4828",
pages = "221--226",
abstract = "The paper describes the QCRI submissions to the task of automatic Arabic dialect classification into 5 Arabic variants, namely Egyptian, Gulf, Levantine, North-African, and Modern Standard Arabic (MSA). The training data is relatively small and is automatically generated from an ASR system. To avoid over-fitting on such small data, we carefully selected and designed the features to capture the morphological essence of the different dialects. We submitted four runs to the Arabic sub-task. For all runs, we used a combined feature vector of character bi-grams, tri-grams, 4-grams, and 5-grams. We tried several machine-learning algorithms, namely Logistic Regression, Naive Bayes, Neural Networks, and Support Vector Machines (SVM) with linear and string kernels. However, our submitted runs used SVM with a linear kernel. In the closed submission, we got the best accuracy of 0.5136 and the third best weighted F1 score, with a difference less than 0.002 from the highest score.",
}

QCRI Machine Translation Systems for IWSLT 16
This paper describes QCRI’s machine translation systems for the IWSLT 2016 evaluation campaign. We participated in the Arabic→English and English→Arabic tracks. We built both Phrase-based and Neural machine translation models, in an effort to probe whether the newly emerged NMT framework surpasses the traditional phrase-based systems in Arabic-English language pairs. We trained a very strong phrase-based system including, a big language model, the Operation Sequence Model, Neural Network Joint Model and Class-based models along with different domain adaptation techniques such as MML filtering, mixture modeling and using fine tuning over NNJM model. However, a Neural MT system, trained by stacking data from different genres through fine-tuning, and applying ensemble over 8 models, beat our very strong phrase-based system by a significant 2 BLEU points margin in Arabic→English direction. We did not obtain similar gains in the other direction but were still able to outperform the phrase-based system. We also applied system combination on phrase-based and NMT outputs.
@inproceedings{durrani2016iwslt,
title={QCRI Machine Translation Systems for IWSLT 16},
author={Durrani, Nadir and Dalvi, Fahim and Sajjad, Hassan and Vogel, Stephan},
booktitle={International Workshop on Spoken Language Translation},
year={2016}
}
Unpublished works
A list of unpublished work that resulted from student research or class projects

VirtualWars: Towards a More Immersive VR Experience
Ensuring that virtual reality experiences are immersive is key to ensuring the success of VR and even VR. However, despite impressive commercial advancements from the Oculus Rift to the HTC Vive, a number of inherent limitations remain when comparing virtual experiences to real experiences: field of view, limb (mainly hand) tracking, position tracking in the world, haptic feedback, and more. In this study we seek to test a number of creative workarounds to create a fully immersive experience with current technological limitations. We found that overall, immersive experiences could be created, but because of the limitations of the technology, limitations had to be imposed on the virtual world such as how the content had to be presented (interactively and not passively), how objects were destroyed, and more.

DeepFace: Face Generation using Deep Learning
Convolutional neural networks (CNNs) are powerful tools for image classification and object detection, but they can also be used to generate images. For our project, we use CNNs to create a face generation system. Given a set of desired facial characteristics, we produce a well-formed face that matches these attributes. Potential facial char- acteristics fall within the general categories of raw at- tributes (e.g., big nose, brown hair, etc.), ethnicity (e.g., white, black, Indian), and accessories (e.g. sunglasses, hat, etc.). In our face generation system, we fine-tune a convolutional network pre-trained on faces to create a binary classification system for the potential facial charac- teristics. We then employ a novel technique that models feature activations as a custom Gaussian Mixture Model in order to identify relevant features for feature inversion. Our face generation system has many potential uses, in- cluding identifying suspects in law enforcement settings.
@article{DBLP:journals/corr/CateDH17a,
author = {Hardie Cate and
Fahim Dalvi and
Zeshan Hussain},
title = {DeepFace: Face Generation using Deep Learning},
journal = {CoRR},
volume = {abs/1701.01876},
year = {2017},
url = {http://arxiv.org/abs/1701.01876},
archivePrefix = {arXiv},
eprint = {1701.01876},
timestamp = {Wed, 07 Jun 2017 14:40:49 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/CateDH17a},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Sign Language Recognition using Temporal Classification
In the US alone, there are approximately 900,000 hearing impaired people whose primary mode of conversation is sign language. For these people, communication with non-signers is a daily struggle, and they are often disadvantaged when it comes to finding a job, accessing health care, etc. There are a few emerging technologies aimed at overcoming these communication barriers, but most existing solutions rely on cameras to translate sign language into vocal language. While these solutions are promising, they require the hearing impaired person to carry the technology with him/her or for a proper environment to be set up for translation. One alternative is to move the technology onto the person’s body. Devices like the Myo armband available in the market today enable us to collect data about the position of the user’s hands and fingers over time. Since each sign is roughly a combination of gestures across time, we can use these technologies for sign language translation. For our project, we utilize a dataset collected by a group at the University of South Wales, which contains parameters, such as hand position, hand rotation, and finger bend, for 95 unique signs. For each input stream representing a sign, we predict which sign class this stream falls into. We begin by implementing baseline SVM and logistic regression models, which perform reasonably well on high-quality data. Lower quality data requires a more sophisticated approach, so we explore different methods in temporal classification, including long short-term memory architectures and sequential pattern mining methods.
@article{DBLP:journals/corr/CateDH17,
author = {Hardie Cate and
Fahim Dalvi and
Zeshan Hussain},
title = {Sign Language Recognition Using Temporal Classification},
journal = {CoRR},
volume = {abs/1701.01875},
year = {2017},
url = {http://arxiv.org/abs/1701.01875},
archivePrefix = {arXiv},
eprint = {1701.01875},
timestamp = {Wed, 07 Jun 2017 14:41:28 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/CateDH17},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Violet: Optimal Image Selection with Machine Learning
People often capture several photos of the same scene to produce the best image. Manually choosing the best image out of the candidates is a time consuming process. We propose an algorithm to automatically detect the optimal image out of a set of candidate images. This eliminates the need for people to spend time evaluating the quality of their images, and allows them to focus on enjoying the memories they have experienced.
RTSift: Creating concise and meaningful review thread representations
We aim to produce a representation of review threads that is concise, interpretable, and preserves much of the meaning of the full text. Further, the representa- tion should be useful for various applications such as summarization, topic modeling, and star-rating pre- diction. This task can be modelled as a feature se- lection problem which consists of two stages: gen- erating feature proposals and filtering/ranking these features. The first stage automatically produces a large set of human-interpretable candidate features, while the second stage reduces that set to achieve a more concise representation.

Multi-User Backend for Meeting Translation
The aim of the Meeting translation project is to provide a platform for multi-lingual meetings. In order for the system to work efficiently, a robust backend is required to augment the automatic recognition and translation services. The existing backend was a very simple proof-of-concept that supported a single user only. The goal of this project was to develop a backend that could support the realtime needs of this project. The backend was also required to support multiple users and meetings simultaneously. Another important aspect of the project was to test the robustness and efficiency of the system. Hence, a statistics collection system was also required that could give us enough information about the different processes in the pipeline to analyze and pin-point the deficiencies in the system. Upon completion, a fully working system was built that could support multiple users and meetings. The system integrated well with the translation and transcription services already available. The statistics collection system was also built and the results from the system were used to analyze the bottlenecks in the processing. The system was tested in both the English and the Arabic language.

I want my Mommy
“I want my Mommy” is a research project that aims to use wireless technologies such as Bluetooth and Wi-Fi to quickly locate people in a large crowd, subsequently reducing the number of lost people. In several crowded areas such as Makkah and Disneyland, people getting separated (specially children and elderly) from their families is a huge problem. This is currently handled manually by making announcements or giving people tags with information written on them. Unfortunately, these solutions do not work in highly crowded areas, both because of the number of people entering the location, and because of the size of these places. We plan to devise an algorithm using commonly existing wireless technologies to reduce the number of lost people by categorizing the crowd into groups without any barrier-to-entry.
Abstract
Poster

Airboats Data Visualizer
Small, autonomous watercraft are an ideal approach to a number of applications in flood mitigation and response, environmental sampling, and numerous other applications. Relative to other types of vehicles, watercraft are inexpensive, simple, robust and reliable. The vision is to have large numbers of very inexpensive airboats provide situational awareness and deliver critical emergency supplies to victims, as well as low cost tools for environmental protection and monitoring. My role in this project was to create a visual interface to analyze and understand the data collected by the boats.
Abstract
Poster

Malware Inc - Web Browsers
Malware Inc. is a project that aims to study the development of Malware on various platforms, such as Web browsers, Social networks and Web engines. I chose Mozilla Firefox as my research platform, as it is the second most widely used web browser today. Having a wide audience adds to the importance of this research project, because the security of a higher number of people is at stake. My role in this research project was to study Firefox extensions, small pieces of code that help in enhancing the browsing experience. These extensions, although very helpful, have the potential to be used for malicious purposes.

Integrating Natural Gestures in Touch Interfaces
This work aims to explore the role of Natural Gestures in daily interaction with computer systems, in particular, their use in the navigation of touchscreen interfaces. Gestures provide a way for users to navigate an interface through intuitive onscreen touch motions and are leading to a shift from traditional point and click interactions to a more natural and physical way of interaction. Given the increased popularity of public touchscreen kiosks in various settings such as airports, hospitals and company lobbies, we designed and built a testbed platform for exploring touchscreen interface design for users of mixed lingual and cultural backgrounds. Inspired by the increasing prominence of gestures in commercial touchscreen devices, our aim was to explore the effects of language and culture on gestures, including the impact of various aspects such as screen size on the usability and practicality of these gestures. We implemented a few of these gestures into our interface, such as natural scrolling, which enables the user to flick their fingers across the screen in order to browse through a list of items. As part of future work, we seek to implement additional gestures into the interface such as screen swiping and to deploy this system on a kiosk at Carnegie Mellon Qatar's campus for the purpose of collecting logs and running experiments. Through these experiments we seek to learn more about the interaction of users with the interface, their preferences and navigation performance, while considering the roles of language and culture in this region.
Abstract
Poster